
在GTIC 2023中国AIGC创新峰会上,微软全渠道事业部首席技术官徐明强进行了主题为《探索AIGC趋势及微软Azure OpenAI在企业的应用》的演讲。
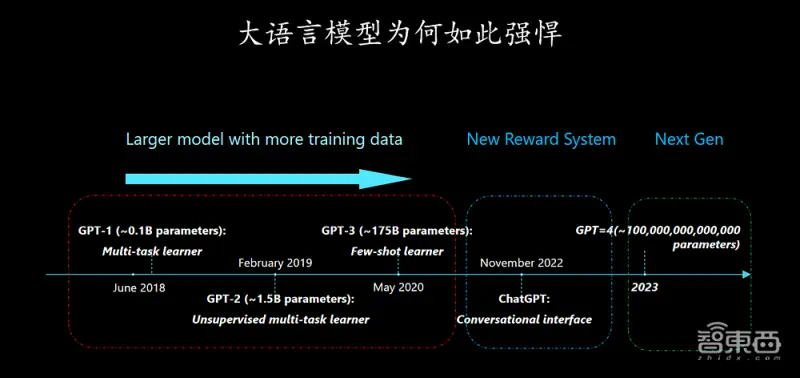
大语言模型参数正在呈现指数型增长趋势。但徐明强称,大语言模型未来仍然会快速增长,因为高质量语料目前仅使用了1/10,剩下的9/10还有待开发。而且现在对大语言模型的质疑会在短短1-2年内就被新的质疑所替代。
这一切的背后都离不开强大算力的支撑,这也决定了所能训练模型的大小、参数。因此,微软Azure与OpenAI合作构建了专为大规模AI训练而设计的AI超级计算机,该计算机拥有28.5万个CPU、10000块GPU。
徐明强把大语言模型比作一块海绵,维基百科、医学或科学论文就是它充分吸收的水,其能力的涌现就需要不断吸收更多的水分。
他后将演讲落脚点归结到企业应用中,在CPU时代,企业应用时思考的问题是如何把商业问题转变为计算问题,也就是通过编译器将应用转为计算问题,如今则转变为如何把各行各业的问题转化为内容处理问题。微软带来的企业级ChatGPT(Enterprise ChatGPT)解决了ChatGPT无法解决的第二步问题:它能把企业内部的数字资产做好索引、做好搜索。
目前,微软企业级ChatGPT的应用场景包括客户服务、销售市场、内容生成、知识管理、辅助决策等。
以下为徐明强的演讲实录:
大家好!
我是微软全渠道事业部首席技术官徐明强。其实我要讲的内容刚刚周明老师已经覆盖了一部分,我主要想在这里分享一些例子。
一、AI模型呈指数级增长,还有9/10高质量语料有待开发
首先,我们今天为什么会聚在这里?一是探讨不断呈指数级增长的语言模型参数,二是分享关于GPT-4的各种参数的猜想。
单从人类的角度来看,这个模型指数曲线实际上还要更加陡峭。
在2015年1月份,AlphaGo打败了欧洲围棋冠军樊麾,但李世石说它只训练过六个月肯定打不过自己,后来的结果我们也都知道了。比尔·盖茨前段时间也对OpenAI说,你们做的东西很好,希望你们能用ChatGPT来通过一个中学的AP(美国大学预修课程,Advanced Placement))考试,盖茨心想,这应该够他们忙个两三年了吧,结果几个月之后就达到了。我们对大语言模型的质疑多也就坚持一到两年,这个质疑就会被新的质疑所取代。
我们有理由相信未来大语言模型还会以指数级增长,因为目前高质量的语料仅使用了1/10,还剩9/10没被使用,新的挑战就是如何找到这剩下的9/10。
当然,这一切都需要背后强大的算力来进行支撑,微软为OpenAI所提供的高度分布式框架AI Supercomputer(超级计算机),是世界第五大超级计算机,拥有28.5万个CPU和1万个GPU,这代表着我们所能训练的模型大小、参数,更重要的是所能训练出的模型的参数。
GPT-3可以达到Fine-tuning(微调)的精度,在60多万份问答答卷中达到70%的分数,可以达到“开卷考试”这个说法了。
为什么大语言模型会如此强悍呢?
其实有一点是我们人类不太清楚的,我们是怎么在教我们的孩子语言的?是不是把语言掰开了、揉碎了一点点教给他,把一些词法分析、语法分析教给他,结果发现效果并不好。
但大模型是怎么做的呢?大语言模型就是一块海绵,把标注好的语料像水一样充分吸收。如果不知道十万个为什么的话,就把维基百科输入进去;不了解医学的话,就把医学论文塞进去,然后在一个个decode layer(译码层)中让能力涌现出来。那什么时候可以涌现呢?就像量子的位置和速度测不准一样,目前这些能力什么时候会涌现还无法测准。
训练其实是比较容易的事情,但让大语言模型学会说话比较难。首先需要它学会听话,叫它做什么,它在理解之后就能做什么。我在和一位网络运营商总裁聊天时他说,以后他都不再需要助手了,他让ChatGPT写的东西完全不会误解他的意思,而且写出来的结果非常好,它就是一个InstuctGPT。
ChatGPT曾经有40位老师,现在的GPT-4已经有1000多位老师了,我们只用授之以渔,告诉它哪一个答案好,它就能输入满意的答案,之前那种一本正经的胡说八道的情况已经减少很多了。之前,GPT-3在我的简历中帮我编造了我很多没有做过的内容,但GPT-4现在已经做得非常真实,完全没有胡说。
二、OpenAI大模型落地企业,NLP项目边际成本趋零
那大模型该怎样在企业中落地呢?
在过去我们处于一个CPU的时代,当CPU刚出来时,大家发现这是一个非常强大的生产力工具,所以大家都在思考如何把商业问题转变为计算问题,如何通过编译器把应用转变为计算问题,把数据库、各行各业生产的、金融的问题转变为计算问题。

同样,我们今天出现的就是一个新的“CPU”,可以把它叫做Chat ProcessUnit或是Content ProcessUnit。今天我们需要考虑的问题,就是如何把各行各业的问题变成Chat的问题,变成一个内容处理的问题。
在过去,NLP是一个非常耗资的工程。为了搜集一个紧张期待症的数据集,需要全球60万的人力来帮助进行数据搜集,这就是一个血汗工厂。而需要大量数据科学家投入精力的工作就像是个“冷汗工厂”,需要不断去调参数、选择模型,这是个risky(充满风险的)的工作。数据科学家的工作如果到了时间没有完成的话,是会让人冒冷汗的,这就意味着一般的企业无法支付得起。
如今的ChatGPT是怎么解决紧张期待症的数据搜集的呢?你只需要跟它说,嗨ChatGPT,告诉你两个例子:第一个紧张期待症的例子是“当彩票号码被宣读出来时,我的手掌开始出汗”,另一个反例是“我无法消除自己的一件事情的紧张不安感”。
告诉它这两个例子之后,就可以开始考试了,向它描述自己的症状:昨天,我把我的手机丢在专车上了。我打给滴滴,结果他们说联系不上司机。过了一个小时之后,我再次打电话,他们说司机没有看到,我心里郁闷,老婆也一直怪我。直到今天,我的心口想起来就会痛,我是否有紧张期待症呢?
ChatGPT的回答中说:“根据您提供的情况,您似乎没有紧张期待症,您貌似是因为手机丢失而产生的担忧和焦虑情绪,以及事后的不安感,这是一种正常的情绪反应。”大家看,它完全理解了这一段话。
我分享这个例子是为什么呢?过去流的那些“血汗”和“冷汗”,如今的企业都不用再流了,过去微软用十亿甚至百亿训练出来的大模型,在座的各位以及世界上每个企业和每个人都将用趋零的边际成本来使用,只要去prompt它就行了。
还有就是写代码,我强烈建议大家用ChatGPT来写代码,写代码只是冰山一角,它真正的生产力在于修代码、修Bug。我晚上修代码时我妻子会跟我说,1点钟了,早点休息吧,我总是说5分钟就行。但码农们都会知道,5分钟之后又会有新的问题出来,5分钟又5分钟,一看时间已经早上五点了。但是我把代码错误告诉给ChatGPT的话,它就会说这个代码有问题,改完后十有八九是正确的,这样的生产力绝对是革命性的。
三、微软与OpenAI加强战略合作,打造五种企业级应用场景
接下来我说一下它的挑战以及如何应对。
挑战主要在两个方面:一是幻觉,二是知识局限。幻觉主要是那些不正确、不相关,以及一些毫无意义的信息、虚假事实,或是它创造了不存在的事件或实体。幻觉产生主要是因为预训练时的答案都是校对好的,但在加强式学习的环境下,打乱了原来的训练模型。在解决方法上“解铃还需系铃人”,加强式学习产生的问题就要用加强式学习来解决。在GPT-4中,发现ChatGPT胡说时就会给它打差评,它就知道回答有问题了。久而久之,这样的问题就会越来越少,终会得到解决。
我发现ChatGPT持续指数性的增长对我的挑战就是,我的PPT变得过时了。
下面我将给大家汇报一下微软将给企业带来的企业级ChatGPT地图(Enterprise ChatGPT Roadmap)。3月,微软发布企业ChatGPT参考架构,各企业IT部门的架构师们可以开始研究如何与IT系统集成,有哪些API可以开始熟悉起来,什么样的系统更适合变成企业ChatGPT。这样的好处在于,在云里面企业用户的订阅是一个单独的ChatGPT实例,里面存放的是各位的私域数据,所有的安全、隐私、防护都有一流的审核来作保障。
具体的应用场景包括客户服务(Chat your Customs)、销售市场(Chat your Web)、内容生成(Chat your Products)、知识管理(Chat your Docs)、辅助决策(Chat your Data)等。

我可以给大家举一个例子,万科的物业大家知道是向谁负责的吗?我之前一直以为是向业主负责,但聊完之后才知道,物业是向政府负责的,当业主的埋怨特别多时,政府其实并不开心,政府需要为业主来考虑。过去的问题在于,当业主打电话、或是通过其它渠道来埋怨、吐槽时,关键词的审核准确率只有70%,如果是非常紧急的负面舆情没有判断到时,会造成一个很糟糕的局面;但用了ChatGPT之后,当天上涨了5个点,近两周已上涨到超过90%,对自然语言的理解给舆情控制带来了如此大的增长。
在内容生成方面,昨天我和一位律师聊天时发现,律所事情太多,当老板要看一千份合同,并且发现中间的合同和标准条款不一样时,员工只能说因为根本没有时间去看这么多份的合同。有了OpenAI的ChatGPT之后,它可以把一千份合同挑出来,随时看有哪些条款和标准条款不一样的。内容生成上我们还有很大的想象空间。
后,AI的注意力虽然都让OpenAI吸引走了,但真正要做一个Enterprise ChatGPT的系统的话,OpenAI还只是初步,我们还要做好第二步的工作,如何把企业内部的数字资产做好索引、做好搜索。ChatGPT现在是一个非常好的开卷考试生,我们要做的是把问题和学习材料递到它手上,这个工作是大家要注意的。
谢谢大家!微软愿和大家一起携手,使用好OpenAI的技术,让每个企业都能成就不凡。
文章来源于网络

科理咨询